『日経Robotics デジタル版(電子版)』のサービス開始を記念して、特別に誰でも閲覧できるようにしています。


今回は学習のエンジンともいえる数値最適化について紹介する。はじめに数値最適化が、どのように学習問題で使われているのかをみてみる。入力xから出力yを予測する回帰を考える。この予測のために、パラメータθで特徴付けられた関数f(x; θ)を学習させる。パラメータθは一般には実数ベクトルである。例えば、線形回帰の場合は
f(x;θ)=<x,θ>+θc
であり、ニューラルネットワークの場合は複数の非線形関数を組み合わせた
f(x;θ)=fk (…f2 (f1(x;θ1);θ2)…;θk)
θ=(θ1,θ2,…θk)
と表される。学習データ{(xi,yi)}に対して、予測関数の誤りの度合いを表す関数を損失関数と呼ぶ。例えば、回帰の場合は、l(x,y,θ)=(y−f(x;θ))2のような二乗誤差を使う。損失関数を使った次のように定義される目的関数
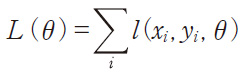
を最小化するようなパラメータθ*を求めれば、学習データをうまく予測できるような関数f(x:θ*)が得られる。
なお、回帰問題ではなく分類問題の場合はヒンジロスやロジスティックロス、確率モデルの学習では負の対数尤度を損失関数として利用する。
さらに学習データに過剰適合してしまう問題を防ぐため、パラメータθについての正則化項R(θ)(例えば|θ|2や|θ|など)を使い、L(θ)+R(θ)を最小化するようなθを求める最適化問題とするのが一般的である。
基本戦略はボールをより低い位置に動かすこと
最適化問題は隆起のあるコースでのパターゴルフのような問題だと考えることができる。ボールの平面上の位置がパラメータ、ボールの高さが関数の値に対応し、最も低い場所へボールを移動させる問題である。
基本的な戦略は今のボールを重力に任せて、より低い方向に持っていくことである。これはL(θ)の勾配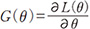 を求め、θ=θ−αG(θ)(α>0は学習率)のような更新を繰り返すことに対応し、最急降下法(GD: Gradient Descent)と呼ばれる。
を求め、θ=θ−αG(θ)(α>0は学習率)のような更新を繰り返すことに対応し、最急降下法(GD: Gradient Descent)と呼ばれる。
しかし、学習の最適化問題の場合、L(θ)が全データから定義されているため、G(θ)を求めるには全ての学習データを毎回調べる必要があり計算量が大きい。そのため、現在は一部の学習データから勾配の推定量を求め、それを使う確率的最急降下法(SGD: Stochastic Gradient Descent)が使われることがほとんどである。
最適化問題が、穴が1つであり、とにかく下って行けば最適解に到達できる凸最適化問題であれば、最適解を理論保証付きで高速に見つけられることが知られている。例えば、(潜在変数の存在しない)サポートベクトルマシンやロジスティック回帰などを使った場合がそれに当たる。詳細については拙著1)などを参考にしてほしい。
ニューラルネットでの最適化の難しさ
一方でニューラルネットワークの学習時の最適化問題は次の2点から難しいことが知られている。1つ目は、局所解が多数存在し、しかもその局所解は層の数に対して指数個だけ増えていくという問題である。ゴルフでいえば、そこら中に穴が無数に空いているようなコースを途中の穴に落とさずにボールを低いところまで持って行くという問題である。
2つ目は、ほとんど傾きがない高原のような領域(プラトー)が存在するということである。プラトーでは傾きがほとんどないため、ボールは転がらず止まってしまう。
それでは傾きが小さい場合は更新幅を大きくすれば良いと単純には考えられるが、鞍点と呼ばれる馬の背中のような場所があり、ここではある方向は平らで別な方向は急であるような場所もある。更新幅を大きくしただけでは、方向が傾きが急な方に向いていれば値は振動、発散してしまう。鞍点ではさらに慎重な更新幅の調整が求められる。このようなプラトーや鞍点が指数個存在する。
また、パラメータの数が大きい(数百万から数十億)ため、基本的にパラメータ数に対して線形の計算量を持つアルゴリズムしか現実的には利用可能ではない。
様々な最適化手法が提案
こうした問題を解決するために様々な最適化手法が提案されてきた。ここでは代表的な手法のAdagrad、RMSProp、Adam、そして最新のSantaについて紹介する。
SGDの学習の際に問題となるのは、学習率αの調整である。このαの大きさが適切でない場合、学習が遅く、振動や発散が起こるという問題が発生する。そのため各次元ごとに学習率をコントロールする方が望ましい。
Adagrad2)は、パラメータの次元ごとのスケールが違う問題に対応できるよう、勾配のノルムの平均を求めておき、学習率をそれで割る。

ただし、gitはt回目の更新時の勾配のi次元目の値である。これは、T回目の学習率をこれまでの履歴から求められた勾配の期待値と√Tで割っているようにみることができる。
RMSPropでは勾配の自乗を移動平均で求め、Adagradと同様にそれで学習率を割る。

RMSPropはAdagradと比べて最適化問題が途中で変わるような場合に対応することができる。鞍点のような局所的に更新率が変わる場合はRMSPropのような移動平均を使う方が良い。これは、自然勾配法における曲率の対角化近似のオンライン推定とみることもできる。
Adam3)は、勾配の1次モーメントと2次モーメントの移動平均を求め、それらを使って学習率をコントロールする。

今の勾配をそのまま使わずにこれまでの移動平均を使うのは、ゴルフでいえば下っている時に勢いがついていて、それをもって降下していくようなイメージである。モーメントを使うことで、収束が速くなることが知られている。なお、Adamの論文にある推定量の修正項は煩雑になるため、ここでは省略している。
最後にSantaと呼ばれる手法4)を紹介する。Santaは現在進展が目覚ましいSGDによるモンテカルロ法を最適化問題に応用した手法である。
また、Santaは焼きなましを導入し、局所解にはまらず、最適解をより効率的に求められると提唱者らは報告している。彼らはSantaがAdamなど既存手法よりもより良い解を見つけられると報告している。Santaのほかにも現在では物理、化学の世界で使われていた様々な技術の導入が盛んになっている。
2)J. Duchi, et al.,“Adaptive Subgradient Methods for Online Learning and Stochastic Optimization,”JMLR,12(Jul),pp.2121−2159, 2011
3)http://arxiv.org/abs/1412.6980
4)http://arxiv.org/abs/1512.07962
Preferred Networks 取締役副社長
 2006年にPreferred Infrastructureを共同創業。2010年、東京大学大学院博士課程修了。博士(情報理工学)。未踏ソフト創造事業スーパークリエータ認定。東京大学総長賞。
2006年にPreferred Infrastructureを共同創業。2010年、東京大学大学院博士課程修了。博士(情報理工学)。未踏ソフト創造事業スーパークリエータ認定。東京大学総長賞。
















































