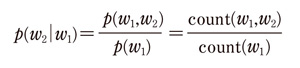日経エレクトロニクス2014年6月9日号のpp.82-87「音声認識に新潮流、ビッグデータやDNNを活用」を分割転載した前編です。
本連載では、実用化が急速に進んでいる音声認識技術の基礎から課題、最新動向を、実装・開発例を交えて解説していく。今回は、音声認識システムの新潮流としてビッグデータの活用を紹介する。
今回は、音声認識研究のこれまでの進歩と最新動向を概観する。まず最初に、前回説明した音声認識の基礎を改めて定式化しておきたい。
言語モデルと音響モデルを最尤推定
人が話す音声とは、その人が頭に浮かべた内容を音波として外に出したものと言える。音声認識は、話し手との間の通信路において音声信号Xを観測して、話された単語列Wを推定することである。
これを数式で表現すると、次のようになる。
p(W│X)≈p(W) p(X│W)
ここでp(W)は、その言語もしくは特定の用途で、ある単語列Wが生成される確率(先験確率)である。これを計算するモデルを「言語モデル」と呼ぶ。もう一方のp(X│W)は、単語列W、正確にはWを構成する音素Sから音声Xが生成される確率である。これを計算するモデルを「音響モデル」と呼ぶ。
音声認識では、言語モデルと音響モデルを用途に応じてあらかじめ推定しておく。言語モデルは、単語列Wの先験確率を、現実の会話におけるWの出現頻度に基づいて推定する。通常は、前後の単語のつながりを統計的に扱うN-単語連鎖モデル(N-gram)で考える。例えば「京都」という言葉が100回現れたうちの20回が「京都大学」という言葉だったとすると、「京都」の次に「大学」が来る確率は20/100とみなせる。w1(「京都」)が生じた時にw2(「大学」)が生じる確率p(w2│w1)は、下記の数式で表現できる。