『日経Robotics デジタル版(電子版)』のサービス開始を記念して、特別に誰でも閲覧できるようにしています。


短期記憶の仕組みは高度なタスクの実現に必要不可欠である。例えば、複数の作業を組み合わせたタスクを実現する場合、自分がこれまでどのような作業をして何が残っているのかを知らなくてはいけない。
このような短期記憶はリカレントニューラルネットワーク(RNN:Recurrent Neural Networks)でも、ある程度実現されている。RNNは内部状態を保持し、各時刻毎に入力を受取って内部状態を更新し出力を決定する。例えば、時刻tに入力x(t)を受け取り、内部状態h(t)をh(t+1)へと更新し、出力y(t)を決定するRNNは次のような関数fとして与えられる。
(y(t),h(t+1))=f(x(t),h(t);θ) (for t=1…n)
=f(Wh(t)+Cx(t))
この例では、入力と内部状態を線形変換して与えた上で、RELUなどの非線形変換を適用している。内部状態をより長期間変えずに保持したい場合はLSTMやGRUなどより複雑な関数を利用する。RNNの場合、内部状態が短期記憶の役割を果たし、過去の情報を符号化した上で記憶している。RNNは自然言語処理や部分観測マルコフ決定過程における記憶を備えた強化学習などで成功を収めている。一方でRNNの記憶容量は内部状態hのユニット数によって上限があるという問題がある。例えば、与えられたキーと値のペアを次々と記憶していき、最後にキーだけが与えられそのキーに対応した値を推定する問題を考えよう。この場合、内部状態で記憶可能な量より多くのペアを記憶しようと思った場合、過去の記憶した情報を忘れてしまう、または記憶が汚染されるという問題が発生する。
この短期記憶の問題に対しては、外部記憶を用意し、内部状態を外部記憶にコピーし、必要になれば外部記憶から内部状態へ読み込むことで解決される。このような方法が実際の脳で実現されているかは分からないが、コンピュータ的には実現は容易であり、Neural Turing Machines1)やDifferentiable Neural Computers2)などで実現されている。
重みに短期記憶を一時的に蓄える
今回はそれとは別に記憶容量を大きく向上させる手法としてニューラルネットワークの重みを一時的に変える“Fast Weight”とよばれる手法3)を紹介する。人や動物の脳では、ニューロン間のあるシナプスが使われた場合、そのシナプスが一時的に増強される現象が知られている。これと同様に、RNNの重みを一時的に変えることで短期記憶、特に連想記憶を実現する。内部状態のユニット数がNの時、そのユニット間をつなぐシナプスに相当する重みの個数はO(N2)であり、内部状態のユニット数Nに比べて非常に大きい。そのため、重みには非常に多くの情報を記憶することができる。
ニューラルネットワークの重みは通常、目的関数を最小化するように学習単位毎(ミニバッチ毎)に確率的勾配法を使って更新する。これらの通常の重みはゆっくり更新されることから“Slow Weight”と呼ぶことにする。一方で、1つの系列を処理する間に一時的に重みを変えていくものを、速く変わっていく重みということでFast Weightと呼ぶことにする。
このFast WeightはN行N列の行列で実現される。A(t)は前の時刻の重みA(t−1)を減衰させ、今の内部状態の外積を加えることで、
A(t)=λA(t−1)+ηh(t)h(t)T
として得られる。今の内部状態の外積を加えたということは、今の内部状態と似た状態の次に今の内部状態が出現しやすいということをモデル化している。例えば、ネコを見たとし、次の時刻にネコの半分が障害物で隠れて見えなくなった場合を考える。この場合、ネコの半分しか見えないにもかかわらずFast Weightが過去の全体が見えている時の内部状態を“思い出し”、次の時刻にはネコ全体に対応する内部状態を作ることができる。
現在の内部状態から次の内部状態は次のように計算する。はじめにSlow Weightを使って次の状態の初期値を作る。
h0(t+1)=f(Wh(t)+Cx(t))
次に、Fast Weightを適当に決めたS回適用し、内部状態を次のように更新する。
hs+1(t+1)=f([Wh(t)+Cx(t)]+A(t)hs(t+1)) (for s=1…S)
この際、最初にSlow Weightで求めた部分は境界条件の役割を果たし、Fast Weightによる影響を加えて定常状態を求める。そして、この内部ループの最後の状態が、次の時刻の内部状態となる。
h(t+1)=hs(t+1)
このFast Weightは、AがN2個のパラメータが存在し、明示的に計算した場合、計算量が大きいという問題がある。また、ミニバッチ学習をした場合、各サンプル毎に別々のAを保持し、計算しなければいけない問題が発生する。そのため、直接Aは扱わずに、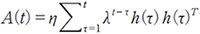 であることに注意すると、A(t)hs(t+1)は次のようにして求められる。
であることに注意すると、A(t)hs(t+1)は次のようにして求められる。

つまり、Fast Weightは現在の内部状態と過去の内部状態との内積h(τ)Ths(t+1)を求め、その値でアテンションをかけて、過去の内部状態を思い出すのに相当する。このようにすればFast Weightの行列を明示的に使わず、アテンションの仕組みのみで短期記憶を実現できる。
このFast Weightの効果を調べるために、Fast Weight論文の著者らは最初の実験として、アルファベットのキーと数字の値のペアの列からなる文字列を入力として与えられた後に、キーのみが与えられ、それに対応する値を報告するタスクの学習を行った。この場合、RNNでは内部状態のユニット数が十分大きくなければキーと値のペアを覚えることができない。RNNの内部状態数が少ないと、Fast Weightを使わない場合は十分記憶することができず、例えば内部状態数が20の時、Fast Weightを使った場合のエラー率は1.81%であったのに対し、RNNの一種であるLSTMのみの場合のエラー率は60.81%であった。
次のタスクとして、画像認識を行った。現在主流である畳み込みニューラルネットワーク(CNN)は画像の全ての位置について同じ計算量をかけて処理をするため、タスクに関係のない大部分の処理が無駄になっている。一方で人や動物は画像を見る場合、はじめに全体を見た後に、その情報に応じて目や鼻など関係しそうな部分に注目することで認識を行う。これと同様に、RNNが画像の部分を順に注目して見ていき、認識を行うことで、CNNと同じ精度が出たと報告された。
このほかにも、複数の画像を総合的に見ないと判断できないようなタスクや、記憶が必要な強化学習のタスクにもFast Weightを使った手法の有用性が報告されている。
Fast Weightは非常に単純なアテンションの仕組みで短期記憶を実現できるということで興味深い研究である。一方で実用的には、過去の内部状態を記憶しておかなければならず、また内部ループでの計算量も大きいという問題点がある。この改良として、例えば内積が大きい部分だけを確率的に思い出したり、またはミニバッチ学習の場合も含めてSlow Weightを効率的に計算する手法が今後重要になると考えられる。
2)A. Graves et al.,“Hybrid computing using a neural network with dynamic external memory,” Nature, vol,538, pp.471-476.
3)J. Ba et al.,“Using Fast Weights to Attend to the Recent Past,” NIPS 2016.
Preferred Networks 取締役副社長
 2006年にPreferred Infrastructureを共同創業。2010年、東京大学大学院博士課程修了。博士(情報理工学)。未踏ソフト創造事業スーパークリエータ認定。東京大学総長賞。
2006年にPreferred Infrastructureを共同創業。2010年、東京大学大学院博士課程修了。博士(情報理工学)。未踏ソフト創造事業スーパークリエータ認定。東京大学総長賞。
















































