『日経Robotics デジタル版(電子版)』のサービス開始を記念して、特別に誰でも閲覧できるようにしています。


人工知能において確率変数を含む最適化問題は様々な問題でみられる。ここでは、その中でも重要な対象関数f(x)の期待値が最大となるような確率分布p(x;θ)を求める問題を考える。
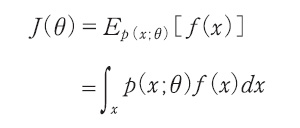
この問題の具体例として強化学習の方策勾配法、生成モデルの変分推定を挙げる。
強化学習の方策勾配法
強化学習は、エージェントが環境の中で次々と行動を決定し報酬を受け取る中で、その将来にわたって受け取る報酬の和を最大化するような問題であった。エージェントの状態がsの時、エージェントの行動aを決定する確率分布がπ(a|s;θ)で与えられるとし、このエージェントの期待収益をJ(θ)とする。また、方策πに従って状態遷移していった時、将来的に状態sになる割引付き確率を
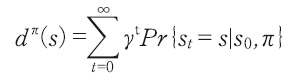
とする、ただし0<γ≦1は報酬の割引率である。この時、期待収益J(θ)のパラメータθについての勾配は

として求められることが知られている、ただしQ(s,a)は状態sの時、行動aをとった時の期待収益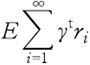 である。これを方策勾配定理と呼ぶ。この定理において重要なのは∇θdπの項がないことである。方策が変わると、将来的に各状態になる確率は変わるのだが、それが勾配へ与える影響はないことである。これにより、本来は行動と状態が独立ではない強化学習の問題において、行動のみの勾配を求めて最適化することができる。この場合、対象関数がQ(s,a)であり、確率分布が方策π(a|s;θ)である。
である。これを方策勾配定理と呼ぶ。この定理において重要なのは∇θdπの項がないことである。方策が変わると、将来的に各状態になる確率は変わるのだが、それが勾配へ与える影響はないことである。これにより、本来は行動と状態が独立ではない強化学習の問題において、行動のみの勾配を求めて最適化することができる。この場合、対象関数がQ(s,a)であり、確率分布が方策π(a|s;θ)である。
生成モデルの変分推定
次の例として、変分法による潜在変数モデルの学習を考えてみよう。はじめに潜在変数zを簡単な分布から生成し、次にデータxをp(x|z;θ)に従って生成するような確率モデル

を考えよう。例えば、
z~N(0,I)
x~N(μ(z;θ),σ(z;θ))
ただしμ(z)とσ(z)は、ニューラルネットワークのようなものを使う。このパラメータの最尤推定は、対数尤度の最大化問題を解く必要があるが、対数尤度は解析的には求まらないので、事後確率分布p(z|x)を近似する別の確率分布q(z|x;φ)を使って、

と求まる下限の最大化を求めることで得られる。ただし、
F(x,z)=logp(x,z)−logq(z|x)
であり、(*)はジェンセンの不等式を利用した。この場合、対象関数がF(x,z)であり、確率分布がq(z|x)である。
勾配最大化
さて、最初の問題に戻り、確率分布がp(x;θ)、対象関数がf(x)の時の期待値
J(θ)=Ep(x;θ)[f(x)]
をθについて最大化する問題を考えてみよう。これは、勾配v=∇θJ(θ)を求め、θ=θ+αvと更新すれば勾配法で求めることができる。ただし、α>0は学習率である。しかし、その勾配を次のように直接求めた場合、

この式は期待値の形ではなく、一般に解析的には解けない。また、xの空間が連続量であったり高次元である場合はxを全て列挙することは困難であり、サンプリングでも解くことはできない。この問題を解決するために2つの方法が提案されている。
尤度比法、REINFORCE
1つ目は制御分野では尤度比法、強化学習分野ではREINFORCEと呼ばれている方法である。
∇θlogp(x;θ)=(1/p(x;θ))∇θp(x;θ)
であることに注意すると、
∇θp(x;θ)=p(x;θ)∇θlogp(x;θ)
と表わせ、p(x;θ)が外にでてくる。この変形を使うと
∇θJ(θ)=Ep(x;θ)[f(x)∇θlogp(x;θ)]
のように勾配推定が期待値の形で表すことができる。
尤度比法による推定値は不偏推定量、つまりサンプル数を増やせば増やすほど正確な勾配に近づく値だが、非常に分散が大きい問題が知られている。例えば、x={0,1}であり、
p(x=1;θ)=999/1000
p(x=0;θ)=1/1000
のような確率の時、サンプリング1000回中、平均して1回だけ、f(1)*1000*∇θp(0;θ)という非常に大きな値がサンプリングされる。この分散を下げるため、次のようなベースラインbを引いた推定量を使う。
Ep(x;θ)[(f(x)−b)∇θlogp(x;θ)]
ベースラインがxに依存しないような値の場合、この期待値も∇θJ(θ)の不偏推定量である。なぜなら、確率分布のパラメータについての勾配の積分は常に0であるためである。

よって

勾配推定値分散が最小になるようなベースラインを厳密に求めるのは大変だが、様々な推定手法が提案されている。例えば、Ep[(f(x)−b)2]が最小になるようなbをオンライン推定で求め、このbを使って勾配を推定する1)。この拡張として、ベースラインを平均場近似をして求める手法2)や、複数サンプルを使ったモンテカルロ推定の他のサンプルの平均をベースラインとして使う手法3)などが提案されている。
また、xがベクトルなど構造を持っている場合、その構造に応じて推定に重要な部分のみを解析的に解いたり、サンプリングをするなどして分散を減らす手法も提案されている4)。
変数変換トリック
もう1つが変数変換トリックである。この変数変換トリックは簡単に使うことができるだけでなく、性能も高いため現在は広く利用されている。変数変換トリックはxが連続量であり、p(x;θ)が微分可能な場合に使える手法である。∊をq(∊)を確率密度関数とする確率変数として、xが
x=t(θ,∊)
という決定的な関数tで表されるとする。例えば、確率密度関数が正規分布N(μ(θ),σ(θ))の場合、
t(θ,∊)=μ(θ)+σ(θ)∊
のような決定的な関数で表される。この場合、勾配は次のように求められる。

ただし(*)では、p(x;θ)dx=q(∊)d∊を使った。この場合、尤度比法とは違ってfの入力に対する勾配

の情報を使って、勾配を求められるため、変数変換トリック後の勾配推定は分散を大きく下げることができる。また、実装も変数にノイズを加えるだけで後は逆誤差伝播法で推定できるので簡単である。
変数変換トリックは、変分法による生成モデル(変分自己符号化器)5)、ニューラルネットワークのパラメータのベイズ推定6)など広く使われており、強化学習でも使われ始めている。
今後の課題
これらの手法を組み合わせることで、確率変数を含む式の最大化問題は解けるようになったが、まだ確率変数が高次元の離散変数の場合や、確率密度関数が微分不可能な場合が問題となっている。また、強化学習の探索と活用のジレンマと同様に、対象関数が複数のピークを持つ場合、勾配情報だけではうまく解けず、どのように探索するかが課題となっている。
2) S. Gu, et al.,“MuProp: Unbiased Back Propagation for Stochastic Neural Networks,” ICLR 2016.
3)A. Minh, et al.,“Variational inference for Monte Carlo objectics,” ICML 2016.
4)M. Tisias, et al.,“Local Expectation Gradient for Black Box Variational Inference,” NIPS 2015.
5)D. P. Kingma, et al.,“Auto-Encoding Variational Bayes,” ICLR 2014.
6)C. Blundell, et al.,“Weight Uncertainty in Neural Networks,” ICML 2015.
Preferred Networks 取締役副社長
 2006年にPreferred Infrastructureを共同創業。2010年、東京大学大学院博士課程修了。博士(情報理工学)。未踏ソフト創造事業スーパークリエータ認定。東京大学総長賞。
2006年にPreferred Infrastructureを共同創業。2010年、東京大学大学院博士課程修了。博士(情報理工学)。未踏ソフト創造事業スーパークリエータ認定。東京大学総長賞。
















































