『日経Robotics デジタル版(電子版)』のサービス開始を記念して、特別に誰でも閲覧できるようにしています。

教師なし学習の目的は大きく4つある。1つ目は観測データの分布を獲得すること、2つ目は観測データと同じようなデータをサンプリングできるようにすること、3つ目は教師あり学習などのタスクに有効な特徴を獲得すること、そして4つ目はデータの隠れた構造を明らかにすることだ。
例えば、1つ目は確率モデルの学習、2つ目はGANによるサンプル生成、3つ目はクラスタリングによる特徴抽出などが対応する。今回はこの4つ目に重要な独立成分分析(ICA:Independent Component Analysis)を紹介する。
データを生成する因子に分解
世の中で観察される多くのデータは複数の因子(または情報源)が複雑に絡まり合って生成されている。例えば、街中で取られた音響データにはすぐ近くの人たちの話し声や遠くの電車の音、木で葉っぱが擦れ合う音などが含まれている。また、車載カメラの映像データには、道路上の複数の車やバイク、道路や背景の木、空の雲などが映りこんでいる。こうしたデータをそれぞれの因子に分解できれば様々な問題を簡単に解くことができる。この問題は「もつれを解く(Disentanglement)」として表現学習の重要なテーマとなっている。
必ずしも因子を抽出できないPCA
例えば、広く使われる主成分分析(PCA:Principal Component Analysis)は、n次元からなる観測データを2乗誤差の意味で最もうまく近似できるk<n個の基底を探し、それらを使ってデータを表現する。別の言い方をすれば観測データを分散に対し最も大きく、直交している方向を大きい順からk個取り出してそれらでデータを表現する。PCAによって得られた基底や各データがどの基底を使って構成されているか(主成分)は、データの傾向を捉えている。一方でPCAは必ずしも因子に対応するわけでなく、因子間で分散の傾向に違いがなければ抽出することはできない。
一方、独立成分分析(ICA:Independent Component Analysis)は因子がお互い独立であるという仮定、また多くの場合、因子の確率分布が非ガウシアンであるという仮定から、データをその生成因子に分解するタスクだ。
例えば、複数の人が話している状況でその音声をマイクで取る場合を考える。マイクがそれぞれの人の声をどの程度の強さで拾えているのか、それぞれの人がどのような音声を発しているのかは分からないが、それぞれの人の声はお互い影響せず独立だと考えることができる。このとき、音響データのみからそれぞれの人の声を分離するタスクがICAだ。
ICAの枠組み
ICAを式で見てみる。m次元からなる観測データがn個ある時、各データを各行に並べたn行m列からなる行列Xを考える。このとき、ICAは
X=f(S)
を満たすような因子(情報源)∈R{n×k}と、その混合関数f:Rk→Rmを求める問題とみなすことができる。ここでは因子はk個あるとし、各次元が独立なk次元ベクトルで表している。特に混合関数が線形である場合、これは
X=AS
のように混合行列Aを使って表すことができる。これまで、混合関数が線形の場合はデータXのみから混合行列Aと独立成分Sを回転などを除いて同定できることが分かっている。また、大規模なデータであっても高速に求められるアルゴリズムが多く提案されている。特に、各データにおける独立成分が疎(多くの成分値が0)の時、データを白色化した後にk-means法を用いて得られた各クラスターはICAのフィルタ(混合行列の逆行列)になることが示されている1)。
一方、現実世界のほとんどのデータでは、混合関数は複数回の非線形な変換を経た後に観測データが得られる。しかし、混合関数が非線形の場合、観測データXを生み出すような無数の独立成分と混合関数の組み合わせが存在してしまい、混合関数と独立成分は不定となる。
時系列データに対する非線形ICA
これに対し、英University College LondonのHyvarinen氏とフィンランドUniversity of Helsinkiの森岡氏らは観測データが時系列データであり一定の条件を満たす場合、非線形独立成分分析が同定可能であり、それが単純なアルゴリズムで実現できることを示した2-3)。以下ではこれらについて説明する。彼らは独立の情報源が非定常の場合と定常のそれぞれで提案している。
情報源が非定常の場合
始めに非定常の場合を紹介する2)。非定常といってもデータは短い時間内では定常とみなせ、長い時間では非定常であるようなゆっくりと分布が変わっている場合を考える。そして、各独立成分がガウシアンも含む指数分布族に従って生成されている場合を考える。この時、独立成分は次のステップで同定することができる2)。
(1)時系列データを一定時間ごとのセグメントに分割し、それらのセグメントについて最初から1,2,3,・・・,kと順に番号をつける。
(2)各時刻のデータを、それが所属するセグメントのラベルがついた教師ありデータとみなす。
(3)各時刻のデータが与えられた時、それがどのセグメントから来たのかを分類するkクラス分類問題をニューラルネットワークNN(x)で学習する。ニューラルネットワークの最後の層はソフトマックスを使ってkクラスの確率分布を出すようにする。
(4)NN(x)がセグメントを完全に分類できるようになった時、NN(x)のソフトマックス直前の層h(x)が独立成分の線形変換後と一致する。そのためh(x)に対して線形の独立成分分析を用いて独立成分、混合行列を同定する。
このアルゴリズムについて直感的な意味を説明する。データの分布はゆっくりと変わっているので、異なるセグメント間では独立成分の生成分布が異なっている。最終層にソフトマックスを使っているので、このモデルによる予測分布q(y|x)はソフトマックス直前の層をh(x)とした時、
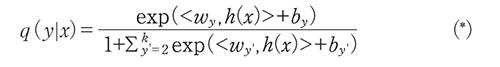
と表される。ただし、一般性を失わずにy=1の時、

としている。分母もそれに応じて1+∑y'=2kexp(<wy',h(x)>+by')となっている。一方、真の事後確率p(y|x)はベイズの定理より
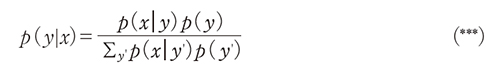
となる。完全に分類できるようになったということは(*)と(***)の確率が一致し、
logq(y|x)=logp(y|x)
が成り立つ。両辺からlogq(1|x)とlogp(1|x)をそれぞれ引き、(*)(**)(***)を組み合わせ整理すると
<wy,h(x)>+by=logp(x|y)−logp(x|1)
となる。
ここで、セグメントは全て同じ大きさなのでp(y)=p(y')も使っている。(*)の分母は、尤度比を扱うことでうまく消去されている。右辺は独立成分に非線形な混合関数を施した後の確率分布であり、本来は混合関数のヤコビアンの行列式の項がでてきて厄介なのだが、これも2つの対数尤度の差分(尤度比)から消去でき右辺も独立成分を線形変換した形が出て来る。
この式が全てのyについて成り立つのでそれらを並べて整理すると左辺がh(x)の(逆行列が存在するような)線形変換であり、右辺が独立成分sの線形変換の式が出て来る。よって、h(x)が独立成分の線形変換後の成分となるので線形のICAを使って独立成分を同定することができる。このアルゴリズムは異なる時間の尤度を比較することからTCL(Time Contrastive Learning)という名がついている。
情報源が定常の場合
次に各情報源が定常の場合を紹介する3)。この場合、仮定として隣接する時刻間s(t)、s(t−1)が一様従属である場合を考える。一様従属とは、p(s(t)、s(t−1))の対数尤度がs(t)とs(t−1)について
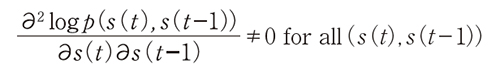
が成り立つ場合をいう。これはs(t)とs(t−1)が独立ではないことよりも強い条件だ。このとき、次のアルゴリズムはデータの独立成分を同定する。
(1)隣りあう時刻のデータ(u,v)=(x(t),x(t−1))を正例(y=1)、異なるランダムな2箇所からとったデータ(u,v)=(x(t),x(t')(t'≠t−1)を負例(y=−1)とする、
(2)r(u,v)=∑iBi(hi(u),hi(v))とし、q(y|u,v)=1/{1+exp(-r(u,v))}としたロジスティック回帰モデルを学習する。ただし、hi、Bi はニューラルネットワークを使う。
(3)訓練事例を完全に分類できるようになった時、hi(x)を並べて得られるh(x)は成分ごとの単調な変換、添字の並び替えを除き独立成分と一致する。
このアルゴリズムは連続する2つのデータの場合と、ランダムに入れ替えた2つのデータを比較することからPCL(Permutation Contrastive Learning)と名前が付けられている。
これについても直感的には、ロジスティック回帰が十分、分類できるようになった時、
r(u,v)=logp(1|u,v)−logp(0|u,v)
となり、尤度比(対数尤度の差)が得られることから説明できる。
これらの成果は、非線形な独立成分分析が教師なし同定可能であり、学習が容易な分類タスクによって実現できることを示した点で画期的だ。
実用上は課題も
一方、実用的にはいくつか課題が残る。1つはこれらのアルゴリズムは与えられたデータを分類器が完璧に分類できるようになることを仮定している。学習は有限のデータで行われ、ニューラルネットワークの表現力の限界もあることから、実際には達成することは困難だ。
また、実際の観察データにはノイズが多く含まれており、情報源も定常、非定常が混ざり合っている。そのような場合にどこまで正確に独立成分分析が実現できるかは未解決である。
今後理論解明が進み、動画のようなデータにもICAが適用できることが期待されている。
2)A. Hyvarinen et al.,“Unsupervised Feature Extraction by Time-Contrastive Learning and Nonlinear ICA,” NIPS 2016
3)A. Hyvarinen et al.,“Nonlinear ICA of Temporally Dependent Stationary Sources,” AISTATS 2017.

















































