前回の記事(2)はこちら、日経エレクトロニクス関連記事はこちら
前回の(2)で解説したように、ルネサスのSTPエンジンを用いたデジタル・テレビ放送送出器の設計では、最終的に利用チップ数を2個にまで削減した。
得られた処理性能は表1のようになった。数値はデジタル・テレビ放送の送出処理をリアルタイムで行うために必要な処理時間を1とした場合の相対的な処理時間である。数値が小さいほど、処理性能が高いことを示す。比較対象は、x86上での純粋なソフトウエア処理の場合(左の列)、XBridgeに搭載されたCPUコア「MIPS 4KEc」での純粋なソフトウエア処理の場合(真ん中の列)である。
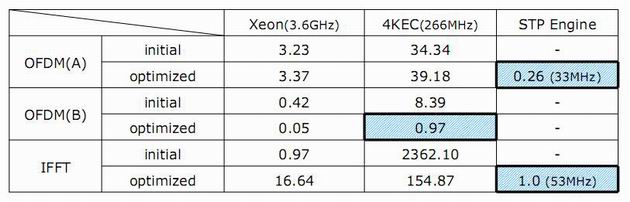
表1 各モジュールの実行時間(相対値)
STPエンジンでは、最初は所望のアルゴリズムをパソコン上や実機上のCPUで実行する。その段階で負荷の重い処理をSTPエンジン上に徐々にオフロードし、並列演算の割合を増やしていく。表1の左から右に沿って最適化を進めていく形になる。
表1で青色のセルが、最適化の結果、最終的に得られた設計での処理性能である。OFDM(A)とはReed-Solomon符号化から畳み込み符号化を経て1次変調までの処理に相当し、下記の図4では赤色の点線で囲んだ「マル1」の処理に相当する。最適化後の最終的な設計では、OFDM(A)の処理はSTPエンジンで実行している。
OFDM(B)は、時間インターリーブなど残りの変調処理であり、これは最適化後の最終的な設計では4KEcコア上で処理している。STPエンジン上の演算器アレイで並列処理せずとも、CPU処理で十分リアルタイムに間に合う負荷の軽い処理ということだ。
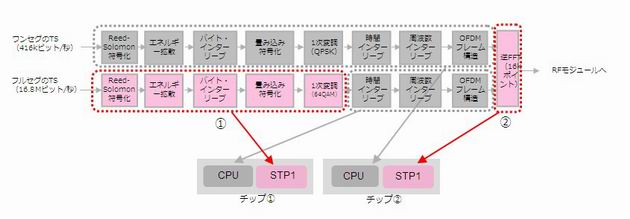
図4 最適化後の構成(2チップ構成)
同じソース・コードが異なる環境で動作
表1で、「initial」とあるのは・・・

















































