内部構造の工夫4000倍
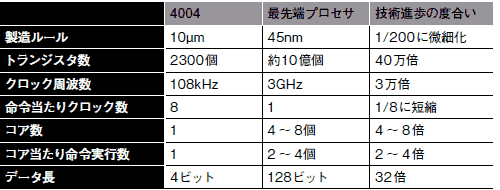
では,アーキテクチャ面では,どれほどの進化があったのだろうか。4004を最先端マイクロプロセサと比較してみると,この40年弱の技術進歩の成果が見て取れる(表1)。アーキテクチャ面の工夫は次の通りである。
(1)命令長/データ長を4ビットから8ビット,16ビット,32ビット,64ビット,128ビットと拡張(32倍の性能向上)
(2)1個の命令を処理するクロック数が当初は8クロックだったが,RISC技術の導入以降,基本的には1命令の処理にかかる時間を1クロックに短縮(8倍の性能向上)
(3)スーパースカラ技術の導入により,1クロックで処理する命令数を複数に増加(4倍の性能向上)あるいはVLIW技術の導入により,1命令で複数命令分の処理を実行(4倍の性能向上)
(4)マルチコア技術の導入により,複数のプロセサ・コアを内蔵させ,並列処理を実現(現状では4~8倍の性能向上)
(1)~(4)の相乗効果によって,4000倍程度の性能向上と試算できる。つまり,クロック周波数の向上も加味すれば,約1億倍の性能向上といえる。
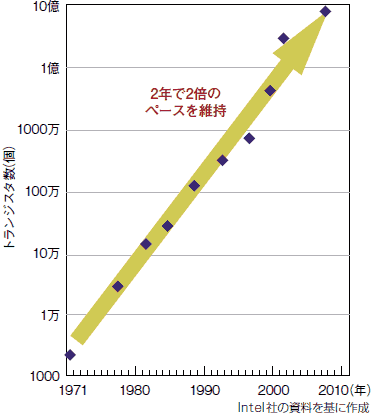
アーキテクチャを進化させる原動力は「ムーアの法則」である。Intel社の創立メンバーでもあるGordon Moore氏は1965年に記した技術論文において,「半導体の集積度は1.5年~2年で2倍になる」と予測した。事実,この法則に従い,半導体技術は進歩した。マイクロプロセサの設計者にとって,豊富に使えるようになったトランジスタ数をいかに有効活用し,性能向上に結び付けるかが腕の見せどころになった(図4)。
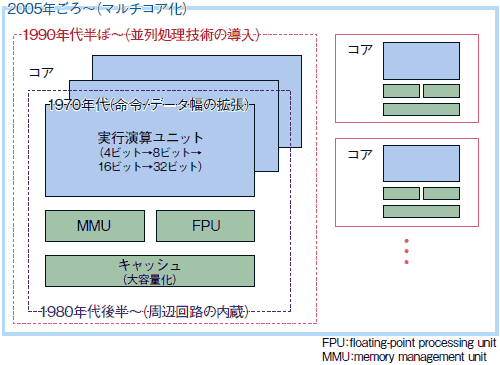
そして,マイクロプロセサの設計者は,メインフレームおよびスーパーコンピュータの内部構造を手本にした。これらのコンピュータがボード・レベルで実現した技術を次々とのみ込み,1チップに集積したのである。1980年代には,MMU(メモリ管理ユニット)やFPU(浮動小数点演算ユニット)といった周辺回路を内蔵すると同時に,オンチップのキャッシュ容量を増大した(図5)。